
Data Loss Prevention (DLP): A Complete Guide for Data Engineers and CDOs

What Is Data Loss Prevention (DLP)?
Data loss prevention (DLP) is a set of technologies, policies, and processes designed to detect, monitor, and prevent the unauthorised transmission, exposure, or destruction of sensitive data across an organisation's systems and networks. At its core, DLP ensures that confidential information — whether personally identifiable information (PII), financial records, protected health information (PHI), or intellectual property — does not leave the organisation's control perimeter without authorisation. For data engineers and Chief Data Officers, DLP is not merely a security checkbox; it is a foundational pillar of any robust data governance framework.
In practical terms, DLP operates across three primary vectors: data in use (endpoints and applications actively processing data), data in motion (data traversing networks or APIs), and data at rest (stored data in databases, data lakes, and cloud warehouses). Modern DLP implementations must span all three vectors simultaneously to be effective.
Why Data Loss Prevention (DLP) Matters in 2026
Regulatory pressure is equally intense. PIPEDA in Canada, HIPAA in the United States, and sector-specific frameworks such as PCI-DSS for payment data all impose legal obligations on how organisations handle, store, and transmit sensitive information. Non-compliance penalties under these regimes can reach millions of dollars, and regulatory bodies are increasingly scrutinising data pipeline architecture during audits — not just application-layer controls.
Beyond compliance, there is a strategic dimension. As organisations build out modern data stacks and democratise data access through data mesh architectures and self-service BI, the number of data consumers — and therefore potential points of data leakage — multiplies. A CDO who does not embed DLP into their data strategy early will face exponentially harder remediation work later. Our experience working with clients across financial services and healthcare confirms this pattern repeatedly.
How Does Data Loss Prevention DLP Work? Core Components and Architecture
Understanding how DLP functions at a technical level is essential for data engineers responsible for designing and operating data platforms. DLP is not a single product — it is an architecture composed of several integrated layers.
-
1. Data Discovery and Classification
Before you can protect data, you must know what sensitive data you have and where it lives. Data discovery tools scan structured and unstructured repositories — databases, object storage buckets, data warehouses, and file shares — and apply classification rules to tag data by sensitivity level. In Snowflake, for example, you can leverage system-defined classification policies using the EXTRACT_SEMANTIC_CATEGORIES function, which programmatically identifies columns containing PII such as email addresses, social security numbers, and credit card numbers.
A typical classification taxonomy used in enterprise DLP programmes includes tiers such as: Public, Internal, Confidential, and Restricted. These tiers map directly to access control policies, encryption requirements, and data retention rules. Pairing automated classification with a well-maintained data catalog dramatically reduces the manual overhead of keeping classifications current as schemas evolve.
-
2. Policy Enforcement Mechanisms
Once data is classified, DLP policies define what is permitted and what is blocked. In a cloud data warehouse context, policy enforcement typically takes several forms:
- Dynamic Data Masking (DDM): Sensitive column values are masked or tokenised at query time based on the querying role, without altering the underlying stored data. Snowflake's native Dynamic Data Masking policies are a first-class feature for this use case.
- Row-Level Security (RLS): Access to specific rows is filtered based on user attributes, ensuring analysts only see data pertinent to their jurisdiction or business unit.
- Column-Level Security: Entire columns containing sensitive fields can be hidden from specific roles regardless of the query issued.
- Network egress controls: Cloud-native tools such as AWS Macie and Azure Purview (Microsoft Purview) monitor and restrict data leaving cloud boundaries via APIs or data exports.
-
3. Monitoring, Alerting, and Auditing
Continuous monitoring is what separates a reactive DLP programme from a proactive one. Query audit logs, access logs, and data export events must be captured and analysed in near real-time. In Snowflake, the ACCOUNT_USAGE schema's QUERY_HISTORY and ACCESS_HISTORY views provide granular visibility into which users queried which columns and when. These logs can be streamed to a SIEM (Security Information and Event Management) platform or analysed directly within your data platform using scheduled dbt models to detect anomalous access patterns.
For organisations building event-driven data architectures, integrating DLP alerting with Apache Kafka pipelines enables real-time detection of data exfiltration attempts across streaming data flows — a capability increasingly important as more sensitive operational data moves through event streaming layers.
Implementing DLP in a Cloud Data Warehouse: A Practical Example
Data platform should brings together:
The following example illustrates how Dynamic Data Masking can be implemented in Snowflake to protect PII columns — a pattern we have deployed in multiple client engagements.
Consider a CUSTOMERS table with columns including EMAIL, PHONE_NUMBER, and SSN. The goal is to ensure that data analysts can run aggregate queries but cannot view raw PII values, while data engineers and compliance officers retain full access.
-
-- Step 1: Create a masking policy for email addresses
CREATE OR REPLACE MASKING POLICY mask_email
AS (val STRING) RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('DATA_ENGINEER', 'COMPLIANCE_OFFICER')
THEN val
ELSE REGEXP_REPLACE(val, '.+@', '****@')
END;-- Step 2: Apply the masking policy to the EMAIL column
ALTER TABLE PROD.PUBLIC.CUSTOMERS
MODIFY COLUMN EMAIL
SET MASKING POLICY mask_email;-- Step 3: Verify policy assignment
SELECT *
FROM TABLE(INFORMATION_SCHEMA.POLICY_REFERENCES(
POLICY_NAME => 'MASK_EMAIL'
));
This configuration ensures that a data analyst querying SELECT EMAIL FROM CUSTOMERS receives ****@gmail.com rather than the raw value, while privileged roles see the actual data. Snowflake's documentation confirms that masking policies are enforced at the compute layer and cannot be bypassed by any query rewrite. This approach integrates naturally with dbt-managed transformation layers where access to Gold or Serving layer models can be role-gated independently of Bronze/Silver ingestion layers.
DLP Tool Comparison: Choosing the Right Approach for Your Stack
Different organisations require different DLP tooling depending on their cloud provider, regulatory environment, and data platform maturity. The table below summarises the key options commonly evaluated by our clients.
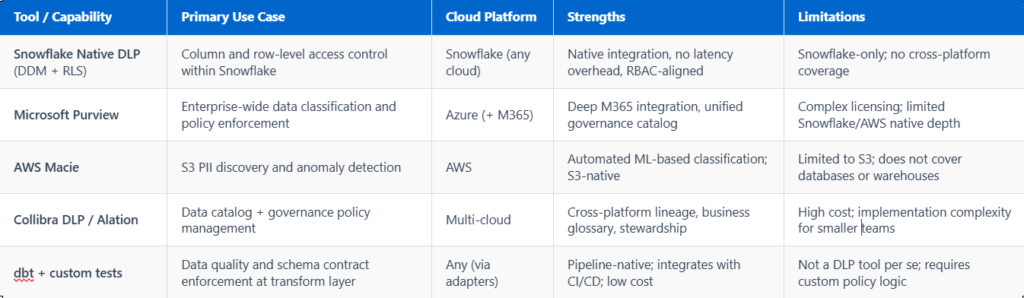
In most cases, the right answer is a layered approach: use platform-native controls (Snowflake DDM, AWS Macie) for enforcement at the storage and compute layer, a data catalog for classification and stewardship, and data contracts to enforce schema and sensitivity agreements between data producers and consumers at the pipeline level.
Common Mistakes and Best Practices in DLP Implementation
Based on our engagements with mid-size organisations across financial services and healthcare, the following mistakes account for the majority of DLP programme failures:
Mistake 1: Treating DLP as a one-time project rather than an ongoing programme. Data schemas evolve, new tables are created, and new pipelines go live daily. A DLP policy applied to today’s schema will have gaps within weeks without automated discovery and continuous classification coverage. Best practice is to integrate classification checks directly into your CI/CD pipeline so that new dbt models or Snowflake tables are scanned for sensitive columns before they reach production.
Mistake 2: Conflating access control with DLP. Role-based access control (RBAC) is necessary but not sufficient. A user with legitimate read access to a table can still inadvertently or maliciously exfiltrate data. DLP adds a layer of content-aware policy enforcement that RBAC alone cannot provide.
-
Best Practices Summary:
- Automate data classification at ingestion time — do not rely on manual tagging.
- Implement masking and RLS policies at the warehouse layer, not just the BI tool layer.
- Audit
ACCESS_HISTORYandQUERY_HISTORYlogs regularly; build anomaly detection models on top of them. - Align DLP policies with your data quality framework so sensitivity tags travel with data lineage metadata.
- Define and enforce data contracts between producers and consumers that explicitly declare sensitivity classifications.
- Conduct quarterly DLP policy reviews as part of your data governance cadence.
How DataKrypton Helps with Data Loss Prevention DLP
At DataKrypton, we design and implement DLP programmes as an integrated component of our data governance and platform engineering engagements — not as an afterthought. Our approach begins with a data sensitivity assessment: we map your current data estate, identify where PII, PHI, or regulated financial data resides, and evaluate the gaps between your existing access controls and a comprehensive DLP posture.
From there, we architect enforcement controls native to your platform — whether that is Snowflake Dynamic Data Masking, Azure Purview classification policies, or custom dbt data contract tests — and integrate them into your existing CI/CD pipelines so that DLP coverage grows automatically with your data platform. We also help you build the monitoring and alerting layer so that your security and data engineering teams have real-time visibility into sensitive data access patterns.
Our clients in financial services particularly benefit from our deep familiarity with PIPEDA, OSFI guidelines, and PCI-DSS requirements — allowing us to map technical DLP controls directly to regulatory obligations. If you are planning a Snowflake or Databricks migration or building out a data governance programme for financial services, embedding DLP from day one is significantly more cost-effective than retrofitting it later.
Ready to assess your organisation’s DLP posture?
About Author:

Debajyoti Kar is the Founder and Principal Data Consultant at DataKrypton AI.
He holds Snowflake SnowPro Core and dbt Developer certifications and has led data engineering and governance
engagements for clients across financial services, retail, and healthcare in Canada and the United States.
Primary sources and technical references
Use these first-party standards and platform references to validate implementation details and current capabilities.
FAQ
Encryption protects data from being read if intercepted, but it does not prevent an authorised user from exfiltrating data they are permitted to access. Data loss prevention (DLP) focuses on monitoring and controlling how data is accessed, moved, and used — including by users who have legitimate credentials. In practice, encryption and DLP are complementary controls and should both be present in a mature data security programme.
Yes. Snowflake provides several native DLP-relevant features including Dynamic Data Masking, Row Access Policies, column-level security, and detailed audit logging via the ACCESS_HISTORY and QUERY_HISTORY views in the ACCOUNT_USAGE schema. Snowflake’s documentation outlines these as part of its Horizon governance suite, which also includes automated data classification for common PII patterns. These native capabilities are a strong foundation, though most enterprise implementations supplement them with a data catalog and egress monitoring layer.
PIPEDA (the Personal Information Protection and Electronic Documents Act) requires organisations to implement “appropriate safeguards” to protect personal information, which in practice includes technical controls consistent with DLP capabilities such as access restriction, monitoring, and breach detection. While PIPEDA does not prescribe specific technologies by name, regulators and courts have increasingly interpreted “appropriate safeguards” to include data classification, access auditing, and breach alerting — all core components of a DLP programme. Organisations subject to PIPEDA should work with legal and compliance counsel alongside their data engineering teams to map technical controls to regulatory obligations.
In a data mesh architecture, data ownership is distributed to domain teams, which creates a federated governance challenge. DLP must be enforced as part of the federated computational governance model — meaning each domain team is responsible for applying classification tags and access policies to the data products they publish, but the platform layer enforces a consistent DLP policy baseline across all domains. Data contracts play a critical role here, as they provide a machine-readable mechanism for declaring and enforcing sensitivity classifications between producers and consumers.
Based on our experience with mid-size North American organisations, the most effective starting point is a focused data sensitivity assessment: identify your top three to five categories of sensitive data (for example, customer PII, payment card data, employee records), map where they currently reside in your data estate, and apply masking or access restriction policies to those specific assets first. Attempting to classify and protect everything simultaneously typically leads to programme paralysis. A phased approach — start narrow, demonstrate value, then expand coverage — is the pattern that consistently delivers sustainable results.
