
Microsoft Fabric vs Snowflake vs Databricks: The 2026 Data Platform Comparison

What Is the Microsoft Fabric vs Snowflake vs Databricks Debate?
When organisations evaluate modern data platforms in 2026, the conversation almost always narrows to three dominant contenders: Microsoft Fabric vs Snowflake vs Databricks. These three platforms represent distinct but overlapping philosophies — a unified SaaS analytics suite, a cloud-native data warehouse built for governed SQL workloads, and an open lakehouse engine rooted in Apache Spark. Choosing between them is not merely a technology decision; it shapes your data team's operating model, cost structure, and long-term architectural flexibility. This guide breaks down exactly where each platform excels, where it falls short, and how to make the right call for your organisation.
Why Microsoft Fabric vs Snowflake vs Databricks Matters More Than Ever in 2026
For mid-size North American companies modernising their data stack, the stakes are tangible: sprawling tool inventories inflate operational costs, fragment governance, and slow down time-to-insight. The choice between Fabric, Snowflake, and Databricks is fundamentally a choice about how you want to organise your data capability — and getting it wrong is expensive to reverse. If you are also weighing a narrower two-way decision, our dedicated Snowflake vs Databricks comparison goes deeper on that specific pairing. For a broader look at assembling your toolchain, see our Modern Data Stack guide.
A Deep Dive Into Each Platform
-
Microsoft Fabric: The Unified Analytics Suite
Microsoft Fabric, generally available since November 2023 and significantly matured through 2025, is best understood as an opinionated, end-to-end analytics platform built on top of OneLake — a single logical data lake underpinning every Fabric workload. It bundles Data Factory (ingestion), Synapse Data Engineering (Spark-based notebooks), Synapse Data Warehouse (T-SQL analytics), Real-Time Intelligence (formerly Real-Time Analytics), Data Activator (event-driven alerts), and Power BI — all under one capacity-based licensing model.
The architectural centrepiece is OneLake's use of the Delta Lake open format, meaning data written by any Fabric workload is accessible to all others without copying. This is a genuine differentiator for organisations already invested in the Microsoft ecosystem — Azure Active Directory, Microsoft 365, Purview for governance, and Power BI licences all integrate natively. Fabric's capacity model (F SKUs billed per compute unit per hour) can offer predictable cost management for organisations with steady, forecastable workloads. However, Fabric's maturity in certain areas — notably robust multi-cloud support and enterprise-grade CI/CD pipelines — still lags behind Snowflake and Databricks as of mid-2026, though Microsoft is closing the gap rapidly.
-
Snowflake: The Governed Cloud Data Warehouse
Snowflake remains the gold standard for organisations that prioritise governed, SQL-first analytics at scale. Its multi-cluster shared data architecture — separating storage, compute, and cloud services layers — allows independent scaling of read and write workloads, which is particularly valuable for high-concurrency BI environments. Snowflake's data sharing and Marketplace capabilities enable cross-organisational data collaboration without physical data movement, a capability unmatched in its class.
As a Snowflake SnowPro Core Certified practitioner, I have implemented Snowflake across financial services and retail clients and consistently find its role-based access control (RBAC), column-level security, dynamic data masking, and row access policies to be the most mature governance primitives available on any cloud platform. Snowflake's support for semi-structured data (VARIANT type, FLATTEN, LATERAL), time travel, and fail-safe storage provides a resilient operational foundation. On the transformation side, pairing Snowflake with dbt is an industry-proven pattern — see our detailed walkthrough in Medallion Architecture with dbt and Snowflake. The primary criticism of Snowflake in 2026 is cost at high-volume data ingestion and the relative immaturity of its native ML and unstructured data capabilities compared to Databricks.
-
Databricks: The Open Lakehouse Engine
Databricks is built around the Delta Lake open-source format and the Apache Spark execution engine, making it the natural home for organisations with complex data engineering pipelines, machine learning workflows, and mixed structured/unstructured data. The Databricks Lakehouse Platform consolidates batch and streaming ingestion (with Delta Live Tables), SQL analytics (via Databricks SQL Warehouses), MLflow-based experiment tracking, and Unity Catalog for unified governance — all on open formats that avoid vendor lock-in at the storage layer.
Unity Catalog, Databricks' metastore and governance layer introduced in 2022 and now deeply integrated across all workloads, provides three-level namespace (catalog.schema.table), fine-grained access control, data lineage, and auditing — capabilities that bring Databricks significantly closer to Snowflake's governance maturity. For teams doing feature engineering, model training, and serving alongside their data pipelines, Databricks' native MLflow integration and Model Serving endpoint create a coherent ML platform that neither Snowflake nor Fabric can fully replicate today. The trade-off is operational complexity: Databricks clusters, autoscaling policies, and notebook-based development require a higher engineering skill floor than Snowflake's SQL-first environment.
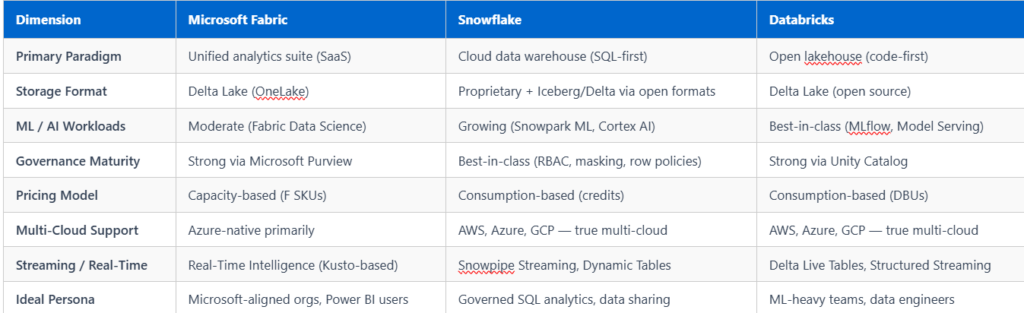
Side-by-Side Platform Comparison: Microsoft Fabric vs Snowflake vs Databricks
A Real-World Implementation Example
After evaluating all three platforms, we recommended Snowflake as the analytical serving layer, with Databricks retained for complex PySpark-based transformation pipelines writing to Snowflake via the Snowflake Connector for Spark. The key implementation detail was enforcing dynamic data masking policies at the Snowflake layer so that regardless of which upstream tool wrote the data, downstream consumers were always presented with appropriately masked output. Here is a simplified version of the masking policy applied to a customer email column:
-
-- Snowflake Dynamic Data Masking Policy
CREATE OR REPLACE MASKING POLICY mask_email
AS (val STRING) RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('ANALYST_PII', 'COMPLIANCE_ROLE') THEN val
ELSE REGEXP_REPLACE(val, '.+@', '****@')
END;ALTER TABLE customer_profile
MODIFY COLUMN email
SET MASKING POLICY mask_email;
This approach resolved the audit finding within one sprint cycle and gave the compliance team a single, enforceable policy layer — rather than attempting to replicate masking logic across both Databricks notebooks and legacy SQL views. For organisations in regulated industries, this kind of data governance in financial services is non-negotiable, and platform choice has a direct impact on how achievable it is. We also implemented a formal data governance framework alongside the migration to ensure policies were operationalised beyond just technical controls.
Common Mistakes and Best Practices When Evaluating These Platforms
Based on our consulting engagements, the following mistakes consistently derail platform evaluations and post-selection implementations:
- Choosing based on demo aesthetics rather than workload fit. Each platform demos beautifully. The critical exercise is mapping your actual workloads — batch ETL volume, query concurrency peaks, ML pipeline frequency, streaming latency requirements — against each platform’s pricing model and execution engine. A workload that looks cheap on Snowflake credits at 10 GB/day can look very different at 10 TB/day.
- Underestimating the governance gap with Databricks. Unity Catalog is powerful but requires deliberate configuration. Many teams deploy Databricks and defer governance setup, accumulating technical debt that is painful to remediate. Establish catalog, schema, and tag taxonomy on day one. Our data quality framework guide covers the organisational practices that should accompany any platform deployment.
- Treating Microsoft Fabric as a drop-in replacement for standalone Azure Synapse. Fabric is architecturally different — OneLake replaces per-workspace ADLS Gen2 silos, and the compute model changed significantly. Migration from Synapse Analytics to Fabric requires careful re-architecture, not a lift-and-shift.
- Ignoring data contract disciplines across platform boundaries. When Databricks writes to Snowflake (or vice versa), schema evolution mismatches are a leading cause of pipeline failures. Implementing data contracts between producers and consumers before cross-platform integration prevents downstream breakage.
- Conflating the ELT pattern with platform capability. All three platforms support ELT natively, but the tooling and performance characteristics differ significantly. Review our ELT vs ETL guide to understand how transformation strategy should influence platform selection.
-
Best practices we recommend:
- Run a time-boxed proof of concept (two to three weeks) on your actual data, not synthetic datasets.
- Model total cost of ownership including compute, storage, egress, and the engineering hours required to maintain each platform.
- Evaluate governance capabilities against your regulatory obligations — not just current requirements but anticipated ones over a three-year horizon.
- Consider the talent market in your geography. Snowflake SQL skills are abundant; Databricks Spark expertise commands a premium in most Canadian markets.
- Design for a Medallion Architecture (Bronze/Silver/Gold) regardless of platform — this pattern translates cleanly across all three and provides a portable data organisation strategy.
How DataKrypton Helps You Navigate Microsoft Fabric vs Snowflake vs Databricks
At DataKrypton, we are a Toronto-based data consulting firm specialising in helping mid-size North American companies make exactly these kinds of platform decisions — and then executing the implementation with precision. We are not a reseller with a preferred platform. Our recommendations are driven by your workload profile, governance obligations, existing technology investments, and team capabilities.
Our typical engagement for a platform evaluation includes:
- A structured workload discovery session mapping your current and future data use cases
- A quantified total cost of ownership model across the shortlisted platforms
- A governance readiness assessment aligned to your regulatory context
- A reference architecture recommendation with implementation roadmap
- Hands-on proof of concept execution if required
Whether you are building on Snowflake with dbt, implementing a Databricks Lakehouse with Unity Catalog, or evaluating Microsoft Fabric for a Microsoft-aligned organisation, our team brings certified, production-tested expertise to every engagement. We also help you think beyond the platform — including Data Mesh architecture for organisations decentralising data ownership, and Data Lakehouse architecture with Apache Iceberg for teams prioritising open format portability.
About Author:

Debajyoti Kar is the Founder and Principal Data Consultant at DataKrypton AI.
He holds Snowflake SnowPro Core and dbt Developer certifications and has led data engineering and governance
engagements for clients across financial services, retail, and healthcare in Canada and the United States.
Primary sources and technical references
Use these first-party standards and platform references to validate implementation details and current capabilities.
FAQ
Microsoft Fabric is a strong choice for organisations deeply invested in the Microsoft ecosystem — particularly those using Azure, Microsoft 365, and Power BI — because of its unified capacity pricing and native integration with Purview for governance. Snowflake, however, remains superior for multi-cloud deployments, high-concurrency governed SQL analytics, and cross-organisation data sharing. In most cases, the decision comes down to your existing cloud alignment and the relative weight of BI-centric versus engineering-centric workloads in your organisation.
Yes, and this is actually a common production architecture — particularly in financial services and retail. A typical pattern uses Databricks for heavy data engineering transformations and ML feature pipelines, then writes curated, governed datasets to Snowflake for SQL-based BI and reporting consumption via the Snowflake Connector for Spark or the Databricks Partner Connect integration. The key discipline required is establishing clear data contracts and schema governance across the boundary between the two platforms to prevent pipeline failures from schema drift.
Microsoft Fabric uses a capacity-based model (F SKUs) where you pre-purchase compute units and share them across all Fabric workloads, which can offer cost predictability for steady-state workloads but may be less economical for highly variable usage. Snowflake and Databricks both use consumption-based pricing — Snowflake charges in credits per virtual warehouse second, while Databricks charges in Databricks Units (DBUs) per cluster node per hour. Based on our experience, Snowflake tends to be cost-competitive for SQL analytics workloads but can become expensive at high-volume continuous ingestion; Databricks can be more economical for large-scale transformation pipelines when clusters are properly sized and auto-terminated.
All three platforms offer enterprise-grade governance capabilities, but with meaningful differences in maturity and approach. Snowflake has the most comprehensive native governance primitives — including dynamic data masking, row access policies, column-level security, and object tagging — making it the preferred choice for organisations with strict regulatory requirements such as HIPAA, PIPEDA, or SOC 2. Databricks Unity Catalog has closed the gap significantly since 2023 with three-level namespace, fine-grained ACLs, and automated lineage tracking. Microsoft Fabric delegates much of its governance to Microsoft Purview, which is powerful for Microsoft-centric organisations but adds a dependency on a separate product for full governance capability.
