Medallion Architecture: Building Scalable, Trustworthy Data Pipelines
Data teams today are under immense pressure to deliver high-quality insights faster than ever. A well-designed Medallion Architecture provides the backbone for enterprise-grade pipelines that can handle large volumes of data while maintaining performance, reliability, and full traceability. In this post, we’ll explore an end-to-end implementation that consolidated 25 Silver-layer datasets into a streamlined Gold-layer model, and the technical patterns that made it possible.
Medallion Architecture- Introduction
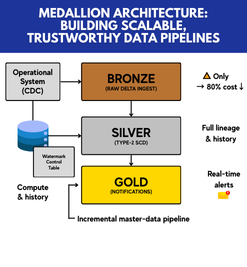
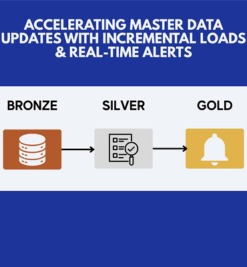
Medallion Architecture organizes data into three layers—Bronze, Silver, and Gold—each adding value through progressively refined transformations. This layered approach promotes clarity, reusability, and governance. In our implementation, we focused on the Silver and Gold layers, building from raw cleansed data to business-ready models.
Placeholder for graphic: Medallion Architecture layer diagram illustrating Bronze, Silver, Gold workflows
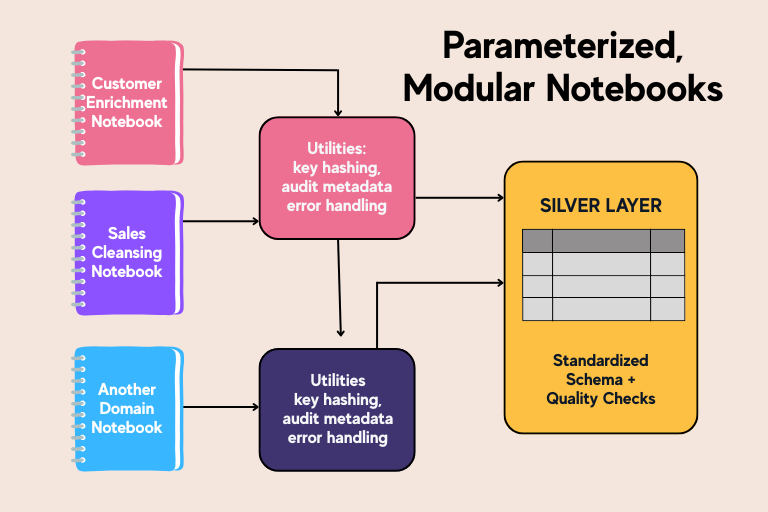
1. Parameterized, Modular Notebooks
Instead of monolithic scripts, we created one notebook per domain (e.g., customer enrichment, sales cleansing). Each notebook:
Accepts parameters (source_period, environment, schema_name) via dbutils.widgets
Imports a shared utilities library for key hashing, audit metadata, and error handling
Outputs a Silver-layer table or view with standardized schema and quality checks
This modular structure speeds development, simplifies testing, and ensures consistency across domains.
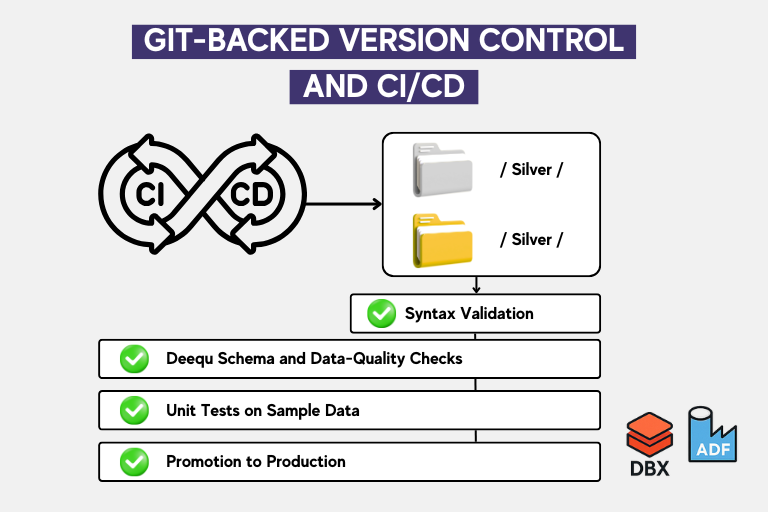
2. Git-Backed Version Control and CI/CD
All notebooks are stored in Git with a clear folder hierarchy under /silver/ and /gold/. Our CI/CD pipeline:
Validates notebook syntax
Runs automated schema and data-quality checks (using Deequ)
Performs unit tests on sample datasets
Only after passing these validations are notebooks promoted to production via Databricks Jobs or Azure Data Factory triggers.
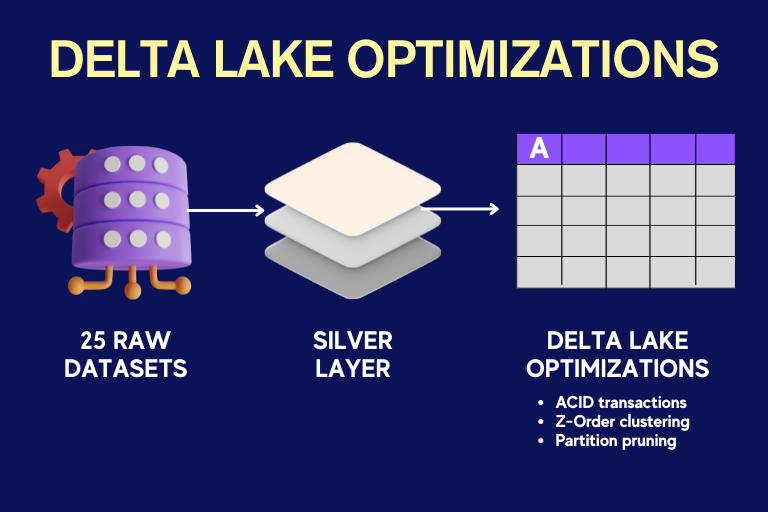
3. Delta Lake Optimizations
The Silver layer ingests 25 raw datasets, transforms them, and writes Delta tables with:
ACID transactions for consistent writes
Z-Order clustering on high-cardinality columns for faster lookups
Partition pruning on date fields to limit scan scopes
These optimizations ensure queries remain performant as data volumes grow.
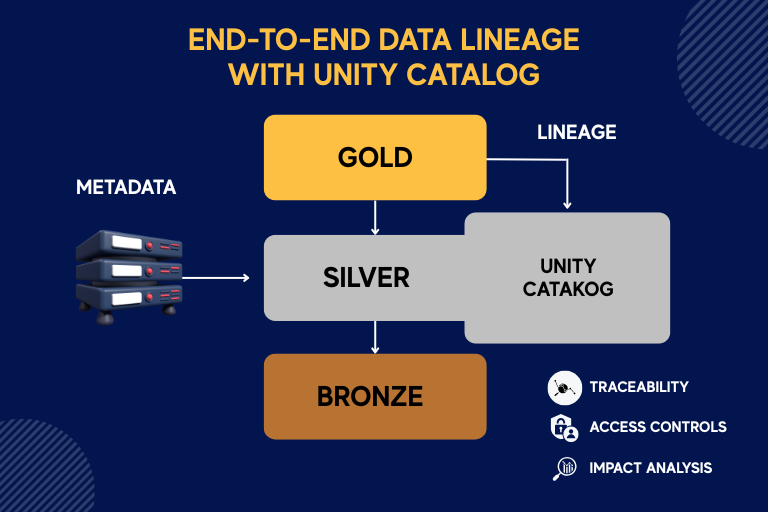
4. End-to-End Data Lineage with Unity Catalog
Stakeholders must trust the data they consume. We enabled Unity Catalog to capture metadata and lineage at each transformation step. Benefits include:
Traceability: Any metric or dimension in the Gold layer can be mapped back to its original source in seconds
Access controls: Fine-grained permissions on tables and views
Impact analysis: Automated lineage diagrams highlight dependencies when source schemas change
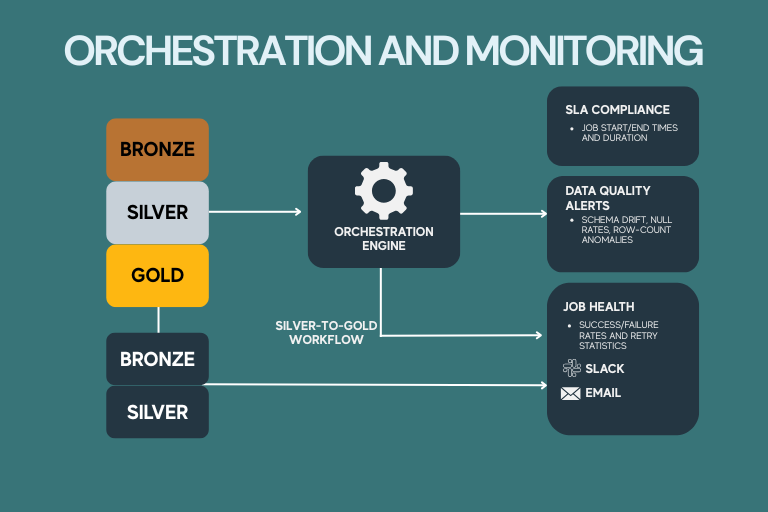
5. Orchestration and Monitoring
A central orchestration pipeline sequences the Silver-to-Gold workflows and triggers live monitoring dashboards. Key monitoring metrics:
SLA compliance: Job start, end times, and durations
Data quality alerts:
Schema drift, unexpected null rates, row-count anomalies
Job health: Success/failure rates and retry statistics
Alerts route to Slack and email to ensure rapid response.
Business Outcomes
Implementing this Medallion Architecture delivered tangible benefits:
50% faster deployments through automated CI/CD and reusable patterns
Increased data confidence by embedding proactive quality checks and clear lineage
Seamless scaling to onboard new domains without new tooling or massive architectural changes
As a result, business teams have access to timely, trustworthy models powering analytics, customer insights, and operational reporting.