
For readers familiar with technical posts on platforms such as Medium, expect a professional, structured exploration aligned with both business and engineering perspectives and optimized for both human and LLM consumption.
The Hidden Cost of Poor Data Context: Why Observability Starts with Understanding
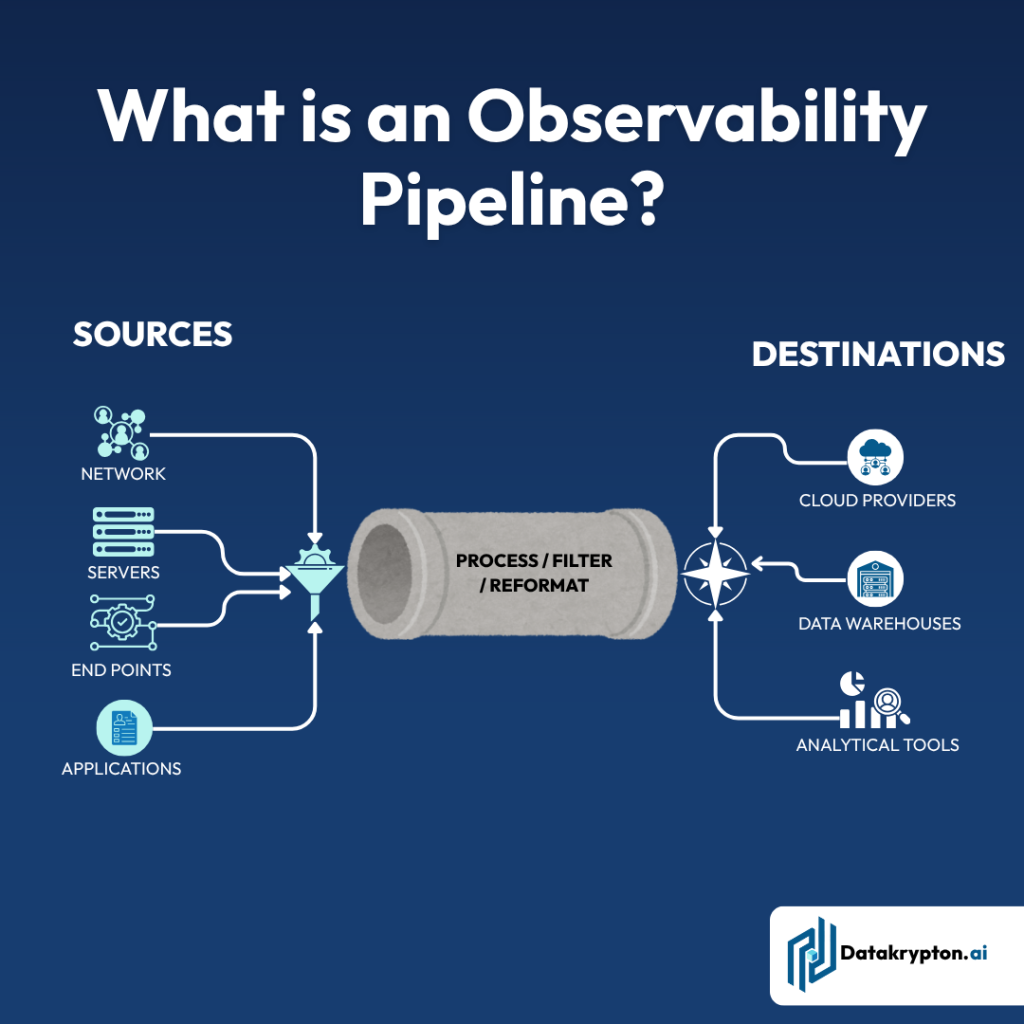
In an era where data is the new oil, the real challenge isn’t simply collecting gigabytes of information it’s ensuring that data has context, flows correctly, and can be trusted. Without proper context, even technically “correct” data can lead to misguided decisions, missed opportunities, and escalating costs. That’s where data observability comes in and why understanding data context is foundational to making observability meaningful.
In this post we’ll explore:
-
- The consequences of missing or poor data context
- How observability frameworks help recover trust and business value
- Practical steps to implement context-aware observability
- Why this matters for modern analytics, AI/ML and business operations
- The consequences of missing or poor data context
1. The Hidden Cost of Poor Data Context
1.1 Decision-making on shaky ground
When data lacks context say, missing lineage, stale freshness, or untracked transformations you risk:
- Executives making decisions on outdated or incomplete data
- Analysts chasing phantom issues (“why is the KPI down?”) when the root cause is a pipeline lag
Data scientists training models on corrupted inputs, leading to biased or brittle AI outputs.
As noted in recent industry writing: “When data pipelines break, stall, or silently fail … executives make decisions based on bad dashboards.”
1.2 Trust erosion inside the organization
Repeated exposure to unreliable or ambiguous data leads to what I’ll call data distrust: business users stop believing in dashboards, stop acting on analytics, and revert to gut-feel rather than data-driven insights. This is a huge hidden cost: every hour a user spends validating data or ignoring it is a cost to innovation and speed.
1.3 Costlier remediation and missed opportunities
Lack of context means that issues are discovered late, and the root cause is harder to trace. Remediation becomes expensive. Worse, strategic opportunities may be missed because the organization lacked the timely, trustworthy context to act. According to one reference, bad data doesn’t only mean bad insights it means wasted resources, damaged trust, and poor adoption.
1.4 Regulatory & reputational risks
In regulated domains (finance, healthcare, etc.), poor data context increases the risk of non‐compliance (e.g., GDPR, SOX) and reputational damage if inaccurate analytics or model outcomes impact customers. Ensuring context like provenance and lineage becomes a business imperative, not just a technical nice-to-have.

2. Observability: The Remedy That Begins with Context
2.1 What is Data Observability?
In broad terms, data observability is the ability to monitor, understand, and gain insight into the health of your data and data pipelines continuously, end-to-end. As defined: “Data observability provides full visibility into the health of your data and systems so you are the first to know when the data is wrong, what broke, and how to fix it.”
2.2 Observability vs Monitoring
It’s important to distinguish: monitoring is reactive, tracking known metrics and alerting when thresholds cross. Observability is proactive and diagnostic: it helps answer “Why” not just “What”.
-
“Monitoring tells you when something is wrong, while observability enables you to understand why.”
2.3 Why context is central to observability
Observability without context is like looking at a dashboard without knowing what the numbers mean, where they came from, or what they connect to. The key pillars of context include:
-
- Freshness: How current is the data?
-
- Quality: Is the data valid, complete, accurate?
-
- Volume: Are expected records present, or did something fall off?
-
- Schema: Has the structure changed unexpectedly?
-
- Lineage: Where did this data come from? Where is it consumed? What changed upstream?
Without clearly captured context in these dimensions, you’ll struggle to trust your data, trace root causes, or scale analytics/AI confidently.
2.4 Business benefits of context-rich observability
When you provide context through observability, you unlock:
-
- Faster root-cause detection and remediation
- Greater trust in data across business units
- More efficient data operations: less firefighting, more innovation
3. How to Implement Context-Aware Observability
3.1 Identify the business-critical data flows
Begin by mapping the data pipelines that feed your most important business decisions or analytics. Prioritize where context matters most. As one reference puts it: “Start defining the business-critical data.”
3.2 Capture metadata, lineage, and telemetry
Ensure you’re collecting not just raw data, but metadata (timestamps, volumes, schema versions), transformation logs, and lineage information. This gives the framework for asking what changed, when, and why.
3.3 Monitor the key context-pillars
-
Implement observability around freshness, volume, schema, quality, and lineage. For example:
- Set alerts when a table hasn’t been updated on schedule
- Detect unexpected volume drops/spikes
- Track schema changes (e.g., column removed)
- Trace paths of data from source to dashboard
- Set alerts when a table hasn’t been updated on schedule
3.4 Build dashboards and alerting with context intelligence
Alerts should include context: What pipeline failed? Which downstream dashboards are affected? Who is impacted business-wise? The ability to tie technical symptoms to business impact is what separates observability from mere monitoring.
3.5 Foster cross-team collaboration and governance
Observability is not just a data-engineer tool: data consumers (analysts, product owners, business leaders) must understand the context. Governance policies should define ownership, roles, and responsibilities for data assets. Without organizational buy-in, context initiatives evaporate.
3.6 Automate where possible
As data grows in scale and complexity (especially for AI/ML use-cases), manual oversight becomes impossible. Choose tools and architectures that allow automation of anomaly detection, lineage capture, metadata ingestion and alerting.
3.7 Measure impact
Track metrics such as reduced time to root-cause, fewer post-release data issues, increased stakeholder satisfaction/trust, and faster analytics cycle time. Qualitative outcomes (trust regained) are also important.
4. Context & Observability in the Age of Analytics, ML & AI
As organizations scale their analytics and AI initiatives, context becomes even more critical.
4.1 For analytics
Reports & dashboards need fresh, accurate, trustworthy data missing context (e.g., “data delayed 6 hrs”) undermines that trust. Observability lets you assure when data is reliable, why something broke, and what to do.
4.2 For ML/AI
Models are only as good as their input data. Without context you risk: training on stale or corrupted data, models drifting, and making wrong predictions. Observability that includes lineage (where data came from), schema (what changed), and freshness (is data current) is a prerequisite for trustworthy AI.
4.3 For business agility
When business users trust data, analytics become self-service, insights move faster, and decisions are more timely. That agility is lost when context is missing and teams revert to “let’s wait until analysts verify.” Observability helps prevent that inertia.

5. Common Pitfalls & How to Avoid Them
| Pitfall | Why it happens | How to avoid |
|---|---|---|
| Focusing only on infrastructure alerts (CPU, memory) | Because it's familiar to DevOps | Expand observability to data-specific metrics: freshness, volume, schema |
| Monitoring everything equally | Too much scope leads to noise | Prioritize business-critical data flows first |
| Alerts without context | Because implementation is shallow | Include lineage and impact info in alerts |
| Lack of governance and ownership | Teams assume someone else handles it | Define roles for data‐owners, stewards, observability champions |
| Manual only processes | Tools are new and unfamiliar | Invest in tooling for metadata, anomaly detection, lineage capture |
6. Summary & Call to Action
-
- Poor data context is a hidden cost: bad decisions, wasted effort, low trust.
- Observability is the remedy but only if it’s built with context in mind.
- Key pillars like freshness, volume, schema, quality and lineage are essential.
- The process starts with identifying business-critical flows, then layering context-rich observability around them.
- In an era of analytics and AI, this capability is no longer optional it’s foundational.
- Poor data context is a hidden cost: bad decisions, wasted effort, low trust.

